I used NLP to gain insight into James Joyce’s Ulysses and David Foster Wallace’s Infinite Jest (“IJ”). It’s kind of useless…but kind of fun. (I will not include my sources of Ulysses and IJ.)
Ulysses, James Joyce
Libraries and Packages
“The Natural Language Toolkit, or more commonly NLTK, is a suite of libraries and programs for symbolic and statistical natural language processing for English written in Python.”
import nltk
# nltk.download('punkt')
# nltk.download('stopwords')
Preparing the Data
# open and read the file
open_jj_ulysses = open('james-joyce-ulysses.txt')
raw_jj_ulysses = open_jj_ulysses.read()
# separate text into a list of words, punctuation marks, and stand-alone characters
find_words_jj_ulysses = nltk.word_tokenize(raw_jj_ulysses)
# use the 'nltk' library to perform analysis
jj_ulysses = nltk.Text(find_words_jj_ulysses)
type(jj_ulysses)
# Out[]: nltk.text.Text
Data Analysis
jj_ulysses[:4]
# Out[]: ['ULYSSES', 'by', 'James', 'Joyce']
print("Our text file of 'Ulysses' has {} words, punctuation marks, and stand-alone characters!"\
.format(len(jj_ulysses)))
# Out[]: Our text file of 'Ulysses' has 314766 words, punctuation marks, and stand-alone characters!
Quotes
Suppose we’re interested in (dialogue) quotes in Ulysses, that is, we’re interested in when characters speak in Ulysses. We know James Joyce uses em dashes to instantiate quotes within Ulysses, which is convenient for data analysis, but we must filter the data.
def quote_indices(jj_work = jj_ulysses):
"""'quote_indices()' returns a list of indices of the beginnings of quotes."""
quote_indices = []
for i in range(len(jj_work)):
if ('—' in jj_work[i]):
# extract em dashes which begin (dialoge) quotes #
if (jj_work[i][0] == '—') & (jj_work[i] != '—'):
quote_indices.append(i)
return quote_indices
Now, we have a function to obtain the indices of those em dashes which begin (dialogue) quotes.
quotes_indices_list = quote_indices()
print("There are {} (dialogue) quotes in 'Ulysses'.".format(len(quotes_indices_list)))
# Out[]: There are 2286 (dialogue) quotes in 'Ulysses'.
We could create a function that returns the first sentence of the nth quote, which first sentence has terminating punctuation of a period (“.”), an exclamation point (“!”), or a question mark (“?”).
def print_quote_n(n, jj_quotes_indices_list = quotes_indices_list):
"""'print_quote_n()' will print a portion or all of the nth quote up to a period, '.'"""
quote = []
idx = jj_quotes_indices_list[n - 1]
while (jj_ulysses[idx] != '.'):
quote.append(jj_ulysses[idx])
idx += 1
if (jj_ulysses[idx] == '!'):
quote.append('!')
break
if (jj_ulysses[idx] == '?'):
quote.append('?')
break
if (jj_ulysses[idx] == '.'):
quote.append('.')
print(' '.join(quote))
for n in range(1, 10):
print_quote_n(n)
# Out[]:
—Introibo ad altare Dei .
—Come up , Kinch !
—Back to barracks !
—For this , O dearly beloved , is the genuine Christine : body and soul and blood and ouns .
—Thanks , old chap , he cried briskly .
—The mockery of it !
—My name is absurd too : Malachi Mulligan , two dactyls .
—Will he come ?
—Tell me , Mulligan , Stephen said quietly .
Words, Words, Words
Now, suppose we’re interested in details about words, such as word count, context, and distribution. We can return the count of a word, punctuation mark, or stand-alone character. Presto! Hmmm…How many times is ‘presto’ used in Ulysses?
word = input('Enter a word: ') # word = 'presto'
print("The word {} is used {} times in 'Ulysses'.".format(word, jj_ulysses.count(word)))
# Out[]:
Enter a word: presto
The word presto is used 3 times in 'Ulysses'.
We can examine the context from a sample of occurences of a word.
word = input('Enter a word: ') # word = 'presto'
jj_ulysses.concordance(word)
# Out[]:
Enter a word: presto
Displaying 3 of 3 matches:
, a mirror within a mirror ( hey , presto ! ) , he beholdeth himself . That y
urope of a month before . But hey , presto , the mirror is breathed on and the
Ill start dressing myself to go out presto non son piu forte Ill put on my bes
We can use the similar() method to return words that appear in the same context as the specified word, though I’m ignorant about the actual algorithm.
word = input('Enter a word: ') # word = 'macintosh'
jj_ulysses.similar(word)
# Out[]:
Enter a word: macintosh
air sea bloom mirror staircase body soul moment all neck voice aunt
right english night man corner water others omphalos
We can create a word dispersion plot.
jj_ulysses.dispersion_plot(['Stephen', 'Bloom', 'Molly', 'macintosh'])
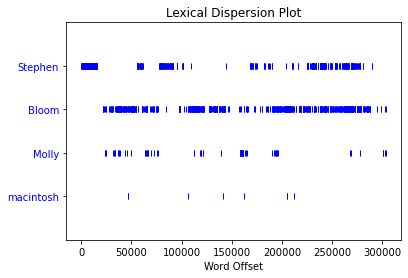
We can create a distribution of words, punctuation marks, and stand-alone characters, and their corresponding frequencies. Further, we can return the ‘n’ most common words, punctuation marks, and stand-alone characters.
frequency_distribution = nltk.FreqDist(jj_ulysses)
frequency_distribution.most_common(20)
# Out[]:
[('.', 19253),
(',', 16334),
('the', 13500),
('of', 8053),
('and', 6624),
('a', 5825),
('to', 4799),
('in', 4668),
('his', 3064),
('he', 2965),
('I', 2782),
(':', 2563),
("'s", 2502),
('that', 2462),
('with', 2369),
('?', 2235),
('it', 2202),
('was', 2129),
('on', 2015),
('for', 1813)]
word = input('Enter a word: ') # word = 'ineluctable'
frequency_distribution[word]
Out[]: 4
Useless Wordcloud
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
from wordcloud import WordCloud, STOPWORDS
mask = np.array(Image.open('cloud.png')) # masking image
def plot_wordcloud(wordcloud):
plt.figure(figsize = (30, 20))
plt.imshow(wordcloud)
plt.axis('off')
jj_ulysses_string = ' '.join(jj_ulysses)
wordcloud = WordCloud(width= 500, height = 700, random_state=1, max_words = 200,\
background_color='black', colormap='rainbow', collocations=False,\
stopwords = STOPWORDS.update(["n't", 's', 'll', 'J', 'Mr', 'Mrs', 'u', 'O', 'said', 'm']),\ # removing uninteresting snippets/words
mask = mask).generate(jj_ulysses_string)
ulysses_wordcloud = plot_wordcloud(wordcloud)
IJ, David Foster Wallace
We’ll repeat the above analysis, without the more interesting information about quotations.
Preparing the Data
# open and read the file #
open_ij = open('ij.txt')
raw_ij = open_ij.read()
# separate text into a list of words, punctuation marks, and stand-alone characters #
find_words_ij = nltk.word_tokenize(raw_ij)
# use the 'nltk' library to perform analysis #
ij = nltk.Text(find_words_ij)
type(ij)
# Out[]: nltk.text.Text
Data Analysis
ij[0:5]
# Out[]: ['INFINITE', 'JEST', 'by', 'David', 'Foster']
print("Our text file of 'Infinite Jest' has {} words, punctuation marks, and stand-alone characters!"\
.format(len(ij)))
# Out[]: Our text file of 'Infinite Jest' has 625334 words, punctuation marks, and stand-alone characters!
Words, Words, Words
Again, suppose we’re interested in details about words, such as word count, context, and distribution. We can return the count of a word, punctuation mark, or stand-alone character. Thinking, I write from my comfy recumbency. Hmmm…How many times is ‘recumbency’ used in IJ?
word = input('Enter a word: ') # word = 'recumbency'
print("The word '{}' is used {} times in 'Infinite Jest'.".format(word, ij.count(word)))
# Out[]:
Enter a word: recumbency
The word 'recumbency' is used 5 times in 'Infinite Jest'.
We can examine the context from a sample of occurences of a word.
word = input('Enter a word: ') # word = 'DMZ'
ij.concordance(word)
# Out[]:
Enter a word: DMZ
Displaying 24 of 24 matches:
lower Allston . The incredibly potent DMZ is apparently classed as a para-metho
r Ebene or psilocybin or Cylert5656 ; DMZ resembling chemically some miscegenat
) altered.5757 The incredibly potent DMZ is synthesized from a derivative of f
ng around with ergotic fungi on rye . DMZ 's discovery was the tail-end of the
wall-watching , the incredibly potent DMZ has a popular-lay-chemical-undergroun
Vietnamese opium , which forget it . DMZ is sometimes also referred to in some
ts of the allegedly incredibly potent DMZ . Pemulis looks all around behind the
, Axhandle , is the incredibly potent DMZ . The Great White Shark of organo-syn
y try to peddle the incredibly potent DMZ around this sorry place ? ’ Pemulis '
ker 's dozen of the incredibly potent DMZ , Sweet Tart-sized tablets of no part
things ring the bell when you key in DMZ . Then they 're all potent this , sin
One monograph had this toss-off about DMZ where the guy invites you to envision
ome massive unspecified dose of early DMZ as part of some Army experiment in Ch
. of the vaunted and elusive compound DMZ or 'Madame Psychosis ' from a small-a
ple the potentially incredibly potent DMZ in predeter-minedly safe amounts befo
hering hangover the incredibly potent DMZ might involve .. . and Axford in the
. Pemulis 's only concern is is this DMZ he got for the WhataBurger detectable
muscimole , which fitviavi 's derived DMZ resembles chemically sort of the way
e temporal-perception consequences of DMZ in the literature are , as far as Pem
Italian lithographer who 'd ingested DMZ once and made a lithograph comparing
ade a lithograph comparing himself on DMZ to a piece of like Futurist sculpture
ard nobody-understands-me dream . The DMZ and Mermanization were incidental. ’
pping their feet. ’ 'Have I mentioned DMZ does n't show up on a G.C./M.S. ? Str
amese opium and the incredibly potent DMZ , Sunshine is pentazocine hydrochlori
We can use the similar() method to return words that appear in the same context as the specified word, though I’m ignorant about the actual algorithm.
word = input('Enter a word: ') # word = 'entertainment'
ij.similar(word)
# Out[]:
Enter a word: entertainment
and way time thing it other man window house moms floor viewer the
room pain air person door guy bathroom
We can create a word dispersion plot.
ij.dispersion_plot(['Hal', 'Steeply', 'Gately', 'entertainment', 'DMZ'])
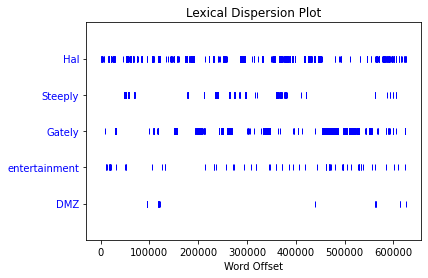
We can create a distribution of words, punctuation marks, and stand-alone characters, and their corresponding frequencies. Further, we can return the ‘n’ most common words, punctuation marks, and stand-alone characters.
frequency_distribution = nltk.FreqDist(ij)
frequency_distribution.most_common(20)
# Out[]:
[('the', 27609),
(',', 26703),
('.', 23451),
('and', 20328),
('of', 14433),
('to', 13047),
('a', 11431),
("'s", 10182),
('in', 8685),
('his', 5142),
('that', 4972),
('with', 4548),
('was', 4338),
('he', 4158),
('on', 4140),
('is', 3944),
('I', 3806),
('it', 3792),
('for', 3617),
('at', 3459)]
word = input('Enter a word: ') # word = 'halated'
frequency_distribution[word]
Out[]: 2
Useless Wordcloud
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
from wordcloud import WordCloud, STOPWORDS
mask = np.array(Image.open('cloud.png')) # masking image
def plot_wordcloud(wordcloud):
plt.figure(figsize = (20, 30))
plt.imshow(wordcloud)
plt.axis('off')
ij_string = ' '.join(ij)
wordcloud = WordCloud(width= 500, height = 700, random_state=1, max_words = 200,\
background_color='black', colormap='rainbow', collocations=False,\
stopwords = STOPWORDS.update(['d', "n't", 'll', 'U', 'M', 'E', 'B', 'T', 'P', 've', 'N', 'F', 'W', 'O']),\
mask = mask).generate(ij_string)
ij_wordcloud = plot_wordcloud(wordcloud)